Python 进程与线程的使用指南 |
您所在的位置:网站首页 › web 共享内存 › Python 进程与线程的使用指南 |
Python 进程与线程的使用指南
|
我们的目标是让 Python 多快好省地完成计算任务,本文实现了进程间的共享内存方法,在分布式计算的同时实现进程间的数据交互。另外,本文还使用代数计算的样例对进程、线程的并行计算性能进行测试和分析,讨论如何选择更合理的计算方式,才能通过并行计算提升整体计算效能。 Python 进程与线程的使用指南[1] 测试结果与使用指南[2]进程与线程[3]进程与线程性能分析[4] 单进程、线程计算速度分析[5]总计算速度分析[6]附录:Python 的进程共享内存方法[7]测试结果与使用指南我的测试机 CPU 是 i7-12700,它有 12 个物理核心,分为 20 个逻辑处理器。因此,我在测试时分别选择 2、5、10、20、30 和 40 个进程、线程进行并行计算。测试后的分析结果如下,它同样可以做为 Python 并行计算的使用指南 多进程的计算速度远快于多线程计算,速度增幅达到了 10 倍;使用多线程计算时,并行计算并不能提升总体计算效率;使用多进程计算时,总体计算效率随进程数量增加而增加,其峰值为 20 个进程;使用多进程计算时,进程数量不宜超过逻辑核心数量,否则会导致 2 个问题 首先,进程数量与逻辑核心数量相同时,性能增加达到天花板;其次,进程数量过多会导致进程挂起,导致有些进程无法在规定时间内完成计算。进程与线程进程(Process)与线程(Thread)是计算机领域的基础概念,虽然在框图中它们可以表示成包含关系,但二者都可以通过并行计算的方法实现高效计算。但由于它们分属不同的“程”,因此并行计算时容易遇到的问题是如何实现进程或线程之间的数据通信。 Processes and Threads[8] Difference between Process and Thread - GeeksforGeeks[9]  线程之间的通信较为简单,因为它们通常属于同一个进程,而进程在内存中拥有自己的独立代码和数据段。只要在这个内存段中的数据指针是一致的,那么就可以通过这个指针实现线程间的数据交互。但进程之间的通信则更加复杂,原因也是进程在内存中拥有自己的独立代码和数据段。这就需要借用共享内存来实现进程间的数据交互,本文的实现方法见附录。 Inter-Process Communication Mechanisms[10] 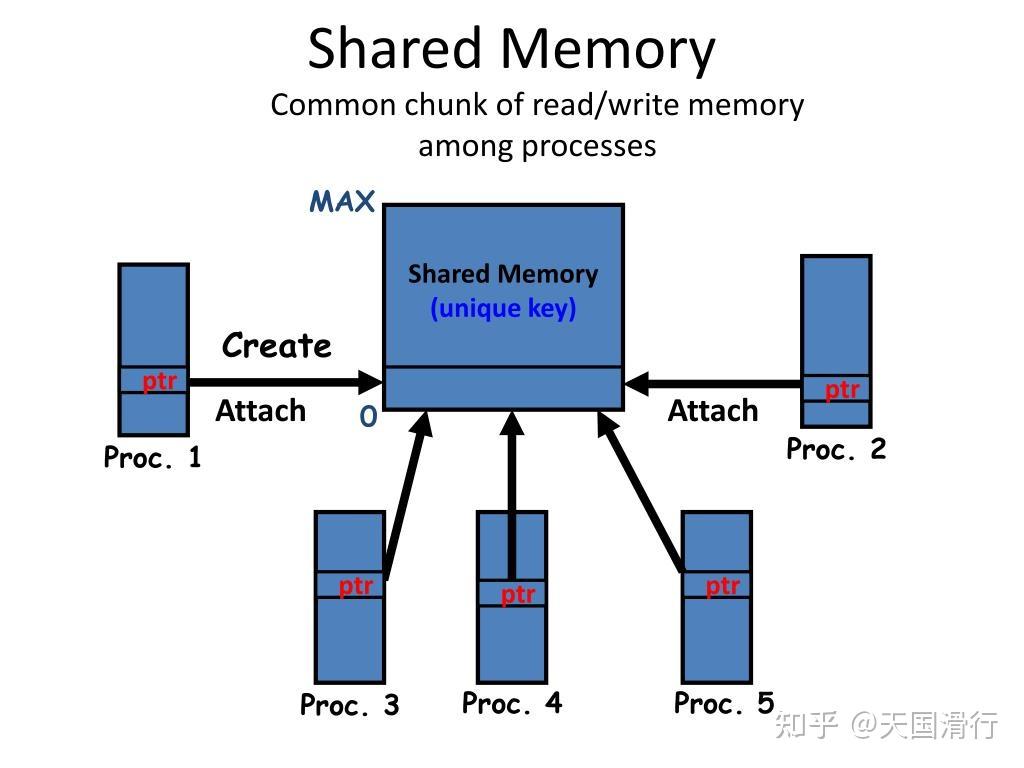 进程与线程性能分析 进程与线程性能分析我们开始对 Python 语言进程与线程的并行计算能力进行分析,选择的计算负载为精确 \pi 值的代数函数,它的特点是计算时间足够长,且迭代计算的复杂度适中,在并行计算时不容易把我的电脑搞崩。 \pi = 4 - 4/3 + 4/5 - 4/7 + 4/9 - \dots \\ 接下来,我们使用多进程、线程的方式进行计算,计算结果被记录在共享内存中。计算时长规定为 10 秒,即在 10 秒钟内各个进程、线程全力计算,之后记录它们在此期间的迭代次数。 单进程、线程计算速度分析下图结果表明,多进程的计算速度远快于多线程计算,速度增幅达到了 10 倍。另外,进程或线程数量越多,则单个进程或线程的计算速度就越低。  总计算速度分析 总计算速度分析下图结果表明,使用多线程计算时,并行计算并不能提升总体计算效率;使用多进程计算时,总体计算效率随进程数量增加而增加。使用多进程计算时,进程数量不宜超过逻辑核心数量,否则会导致 2 个问题,首先,进程数量与逻辑核心数量相同时,性能增加达到天花板;其次,进程数量过多会导致进程挂起,导致有些进程无法在规定时间内完成计算。  附录:Python 的进程共享内存方法 附录:Python 的进程共享内存方法python 提供了 multiprocessing.managers 包来实现进程间数据交互,本文实现的样例代码如下。 # Setup shared memory and assign them into processes from multiprocessing.managers import SharedMemoryManager with SharedMemoryManager() as smm: sl = smm.ShareableList([0 for _ in range(num_jobs * num_index + 1)]) for job in jobs: p = method(target=compute_pi, args=(sl,), kwargs=job, daemon=True) p.start() t = Thread(target=monitor, args=(sl,), daemon=True) t.start() # Run for 10 seconds time.sleep(duration) sl[-1] = -1 for job in jobs: job['iteration'] = sl[job['idx_session']] * job['base_iterations'] job['pi'] = sl[job['idx_pi']] job['start'] = sl[job['idx_start']] job['stop'] = sl[job['idx_stop']] job['method'] = method_name job['jobs'] = num_jobs print('Final', sl) 参考资料[1] Python 进程与线程的使用指南: #python-进程与线程的使用指南 [2] 测试结果与使用指南: #测试结果与使用指南 [3] 进程与线程: #进程与线程 [4] 进程与线程性能分析: #进程与线程性能分析 [5] 单进程、线程计算速度分析: #单进程线程计算速度分析 [6] 总计算速度分析: #总计算速度分析 [7] 附录:Python 的进程共享内存方法: #附录python-的进程共享内存方法 [8] Processes and Threads: https://web.stanford.edu/~ouster/cgi-bin/cs140-winter12/lecture.php?topic=process [9] Difference between Process and Thread - GeeksforGeeks: https://www.geeksforgeeks.org/difference-between-process-and-thread/ [10] Inter-Process Communication Mechanisms: https://www.slideserve.com/ipo/inter-process-communication-mechanisms |
【本文地址】
今日新闻 |
推荐新闻 |